摘 要:针对胡麻倒伏检测中存在的背景复杂以及模型计算量大等问题,该研究提出了一种改进DeepLabV3+的轻量化胡麻倒伏识别模型。首先采用轻量化主干网络MobileNetV2,减少模型的训练时长;然后引入坐标注意力机制CA(coordinate attention),增强模型对小范围倒伏区域的定位能力;再次,将原有的交叉熵损失函数(cross-entropy loss, CE -Loss)替换为更适合倒伏识别情境下的Focal Loss,同时在总损失中添加Dice Loss,增强数据类别不平衡情况下的识别效果。试验结果表明,改进后的DeepLabV3+模型在胡麻倒伏识别任务中提升了精度和效率,平均精确率达95.96%,平均交并比(mean intersection over union, mIoU)和平均像素精度(mean pixel accuracy, mPA)分别达到了92.55%和96.11%,相比HRNet、PSPNet、U-Net、SegNeXt-S、DeepLabV3+模型其mIoU分别提升1.08、3.74、3.06、11.79和1.59个百分点,mPA分别提升0.92、2.80、1.58、8.68和1.17个百分点;模型训练时长由原DeepLabV3+的27.3h缩短为14.2h;同时满足了实时性识别要求,平均检测帧率为83帧/s。该研究为农业场景下的实时倒伏检测及收割机作业优化提供了可行的技术方案。
关键词:无人机;遥感;语义分割;胡麻;DeepLabV3+;倒伏区域识别;轻量化
引言
油用亚麻,俗称胡麻,是中国西北地区和华北地区的重要油料作物之一[1],提高胡麻产量和种植效益、扩大生产规模是缓解中国胡麻油供给的重要举措[2]。倒伏严重阻碍着胡麻的正常生长发育及产量的提高,据统计,倒伏后单株胡麻产量和含油率分别下降45.35%和4.41%[3]。倒伏后的作物植株贴地,导致收割机的割台难以有效收割作物。在收割过程中,影响后续的收割作业,造成收割损失[4],故需调整割台的高度和角度。提取倒伏面积是调整割台的前提,因此对于倒伏区域的识别至关重要。
当前的倒伏面积提取方法主要通过无人机遥感影像获取大面积田间作物数据,并利用人工智能模型对图像中的倒伏区域进行提取。利用无人机遥感技术对不同作物倒伏情况进行研究并取得一定进展[5-6]。这种方法在大范围农田的倒伏面积检测中表现出良好的效果。赵静等[7]利用无人机遥感平台获取小麦倒伏后的可见光图像,通过融合图像特征的方法提取倒伏小麦信息。李广等[8]基于两期无人机可见光遥感图像,结合特征参数与K-means算法提取冬小麦倒伏信息,取得了较高的提取精度。杨蜀秦等[9]以小麦灌浆期和成熟期的无人机可见光遥感影像为基础,提出了一种改进的DeepLabv3+模型,能够有效捕捉这两个生长阶段的倒伏特征,并准确识别不同时期的倒伏区域。申华磊等[10]通过无人机获取遥感图像,提出了一种融合多尺度特征的倒伏面积分割模型Attention_U2-net,该模型在小麦倒伏面积提取中表现出较强的鲁棒性和准确性。郑二功等[11]以无人机遥感在玉米倒伏灾害评估中的应用为背景,采用FCN模型分割玉米倒伏区域。臧贺藏等[12]利用无人机遥感平台获取的小麦倒伏可见光图像,对比了多种深度学习模型,为小麦受灾面积的评估提供了重要支持。郑权等[13]提出了一种基于无人机可见光影像的油菜倒伏分类方法,融合多尺度特征和注意力机制,设计了图像分类模型NGnet,在油菜倒伏分类任务中取得了较高的精度。王薇等[14]提出了一种基于无人机航拍获取苎麻倒伏信息的方法,利用机器学习模型高效识别苎麻倒伏地块。刘美辰等[15]提出了一种融合激光距离强度信息的中值滤波算法,结合激光距离信息和强度信息,实现了对小麦割茬区、倒伏区和未倒伏区的识别。
以无人机遥感数据为基础的研究目前应用广泛。然而,无人机遥感数据不能直接应用于收割机的作物收获指导。机器视觉已被广泛应用在农田作业中的路径规划等多个方向,人工智能的迅速发展也为农业领域的发展提供了强大的技术支撑。结合机器视觉应用于农作物倒伏领域的研究目前尚少。WEN等[16]针对联合收割机作业范围内的倒伏小麦,提出了一种基于双目相机的实时检测方案,可在2s内精确定位倒伏区域、勾勒轮廓并测算其面积,满足收获过程对速度与精度的双重需求。杨悦等[17]提出一种基于激光雷达的稻麦倒伏区域实时监测方法,最终倒伏面积识别的mIoU达到了95.26%,处理每帧点云数据的平均耗时为0.875s。
结合收割机影像对倒伏区域进行识别的研究尚少,且当前基于深度学习的农作物倒伏区域识别大都关于小麦、玉米或水稻等作物,鲜有胡麻。因此本文提出,将相机置于收割机顶部,通过对胡麻田地实时拍摄来收集数据,收割机摄像数据可直接用于指导收割机作业,例如调整留茬高度,优化收割效率,减少作物浪费。本文通过一种改进的DeepLabV3+模型结合收割机倒伏影像对倒伏区域进行识别,为胡麻的智能化收割提供技术支持。
1 材料与方法
1.1 研究区域
本研究于2024年6月在甘肃省定西农科院油料作物研究站(34°26′N,103°52′E)开展试验。试验区属中温带偏旱区,平均海拔2050m。根据2024年6月的气象数据,当月平均日照时数为8.7h,平均气温为约为22.05℃,最高气温为28.7℃,最低气温为6.5℃,风力平均3.5级。定西市年平均气温8.8℃,年平均总降水量472.4mm。
1.2 数据获取
拍摄数据时间为2024年6月,选取天气晴朗时进行拍摄。机器视觉因其信息丰富、环境适应性强等优点,成为农业、工业、医学等多个领域的基础技术[18]。本文选择具有高像素和高稳定性的大疆Mini 4 Pro,将其固定于收割机顶部进行数据采集,拍摄像素为4800万像素。它还具有强大的色彩表现,支持HLG色彩模式,可以提升画面的动态范围,在复杂的光照条件下,比如收割机在阳光下作业时,HLG模式可以更好地平衡亮部和暗部的细节,使胡麻倒伏的画面更加自然和真实。此外还支持10-bitD-LogM色彩模式的记录,在拍摄数据时,无论在阳光直射下还是阴影区域,都能更好地保留细节,便于后期对数据进行预处理。
1.3 数据预处理
对于收割机拍摄的486张4032×2268像素大小的原始图像进行筛选去重。由于接近成熟期的胡麻倒伏和未倒伏区域的差别较为显著,胡麻的种植密度较大,对于未倒伏区域的胡麻可以显著看到胡麻籽以及开花部位,而对于倒伏区域的胡麻,则是看到胡麻茎秆,甚至在倒伏严重区域可以看到地面。本试验采用labelme版本3.16.7对图像中胡麻倒伏区域进行标注,标注的数据集包括倒伏和背景两个类别,示例图如图1所示。标注后对图像和标注文件进行随机数据增强以增加模型的泛化能力,包括切割、缩放、旋转、高斯模糊、添加噪声、色域变换等,得到处理后的数据5346张,达到了模型的训练要求。把数据集按照8:2进行划分训练集和验证集,最终得到4276张图像作为训练集,1070张图像作为验证集。

图1 图像标注事例
1.4 DeepLabV3+语义分割模型
语义分割模型是一种用于图像处理的深度学习技术,旨在将图像中的每个像素分类到特定的类别中。与传统的图像分类任务不同,语义分割不仅识别图像中的物体,还精确到像素级别,为每个像素分配一个类别标签。核心思想是通过卷积神经网络(CNN)提取图像特征,然后利用这些特征对每个像素进行分类。通常由编码器和解码器两部分组成,编码器负责提取高层次的特征,解码器则将这些特征映射回原始图像尺寸,生成像素级别的分类结果。
DeepLabV3+[19]是一种高效的语义分割模型,其编码器-解码器结构[20-21]结合了高层次语义特征和空间细节恢复能力,在Deeplabv3的基础之上添加Xception[19]作为模型主干网络,进一步提高了分割精度,同时通过深度可分离卷积减少计算量并保持特征提取能力,利用空洞空间金字塔池化(ASPP)捕获多尺度上下文信息,提升对复杂场景的分割效果。ASPP的输出式为
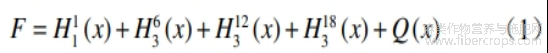
式中F是输出特征图,x是输入特征图,H11(x)是1×1卷积,H36(x)是3×3的膨胀率为6的空洞卷积,H312(x)是3×3的膨胀率为12的空洞卷积,H318(x)是3×3的膨胀率为18的空洞卷积,Q(x)为池化层。空洞卷积的引入扩大了感受野,避免了空间信息丢失。
DeepLabV3+在提高模型分割效果的同时也增加了模型的参数量及复杂度,使得模型的训练时长增加,本文对于其模型结构进行轻量化的改进,以适应对于胡麻倒伏区域识别的实时性要求。
1.5 改进的 DeepLabV3+网络结构
本研究对DeepLabV3+的改进体现在将主干网络Xception替换为MobileNetV2、增加CA注意力机制并放置于ASPP之后以及将传统损失函数CE_Loss替换为混合Focal Loss+ Dice Loss。采用基于MobileNetV2的轻量化架构,通过其特有的倒残差结构和线性瓶颈层设计,在保持模型识别精度的同时大幅降低了计算复杂度。针对倒伏区域的空间分布特性,引入的坐标注意力机制(CA)通过双向池化操作精确捕捉位置信息,并生成具有空间感知能力的注意力权重,有效强化了模型对不规则倒伏区域的定位能力。针对农业场景中常见类别不平衡问题,采用FocalLoss和Dice Loss的组合策略,二者的协同作用使模型在小样本和类别不平衡条件下的识别稳定性得到明显改善。改进模型与原DeepLabV3+相比在提高分割效果的同时降低了模型的参数量及复杂度,增强数据类别不平衡情况下识别效果的同时提升模型对倒伏区域识别的实时性。改进后的模型结构如图2所示。
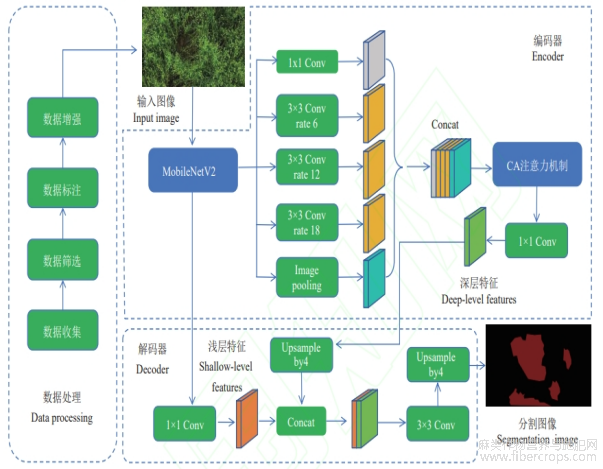
图2 改进后DeepLabV3+网络结构
MobileNetV2被用来捕捉图像的关键特征,输入图像首先经过一个卷积层增加通道数,然后通过多个不同的倒置残差结构逐步提取更深层次的特征。一方面通过跳跃连接将编码器得到的特征输入到解码器中进行处理,另一方面输入多膨胀率(6,12,18)的空洞卷积,也就是ASPP当中,这些卷积操作可以在获取不同尺度上下文信息的同时不增加额外的参数。在ASPP之后,与浅层特征融合之前,通过CA注意力机制增强深层特征的表示,最终在解码器中将深层特征与浅层特征进行融合,从而提升分割模型的整体性能。
1.5.1 MobileNetV2主干模块
由于DeepLabV3+模型预测速度慢、计算量大,本文改进了DeepLabV3+的主干网络,将Xception替换为轻量化网络MobileNetV2[22],旨在解决在作物收割过程中的实时性要求较高的问题,能够在保持较高精确度的前提下,降低训练成本,提升模型的运算速度。
MobileNetV2是一种针对移动设备和资源受限环境优化的高效卷积神经网络架构。它在继承MobileNetV1深度可分离卷积的基础上,创新性地采用了倒置残差结构和线性瓶颈设计。倒置残差块包含步长(stride)为1和2两种,设计特定比例组合形成高效的多尺度特征提取结构。以步长stride=1为例,输入的图像依次经过1×1卷积、深度可分离卷积,使用ReLU6作为激活函数,再利用1×1卷积降维,如图3所示。通过在高维扩展层引入ReLU6增强非线性变换,同时保持低维瓶颈层的线性特征,实现了在牺牲少量精度的同时减少计算量和内存占用,并且保持甚至提升模型的精度表现。MobileNetV2被广泛应用于图像处理模型的主干网络之中[23-26],用其替换掉原有的主干网络能够更加高效的完成作物倒伏识别任务。
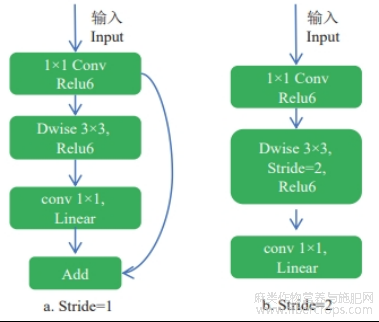
图3 MobileNetV2倒置残差块
1.5.2 CA注意力机制模块
坐标注意力机制(coordinate attention, CA)[27]一种用于提升卷积神经网络(CNN)性能的注意力机制。CA机制在移动网络(如MobileNetV2和MobileNeXt)中非常有效,显著提升了模型在图像分类、目标检测和语义分割任务中的性能[27]。CA的核心思想是将通道注意力分解为两个1D特征编码过程,分别沿水平方向和垂直方向聚合特征。这样不仅能捕获通道间的关系,还能保留精确的位置信息,从而更准确地定位目标。胡麻倒伏通常是发生在局部区域,倒伏区域的位置信息对识别至关重要,CA可以通过分解水平和垂直方向的注意力机制,从而精确捕捉数据的空间位置信息,增强模型对倒伏区域的敏感性。在数据图像中,倒伏的面积可能较小,传统方法容易忽略,CA通过全局池化和位置编码,可以增强模型对小尺度倒伏区域的识别能力。同时对于作物收割的实时性要求,CA的计算开销较小,在处理大量农田图像时,能在不显著增加模型复杂度的同时提升模型性能。该注意力机制结构如图4所示。
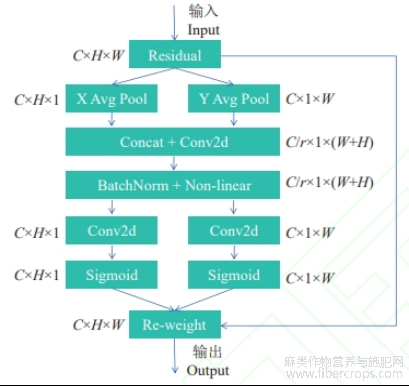
图4 坐标注意力模块
注:C,通道数;H,输入特征图高;W输入特征图宽;Residual,残差连接;Avg Pool,平均池化;r,降维比率;C/r,降维后的通道数;Re-weight,生成的注意力权重与原始输入特征图进行逐元素相乘,对输入特征图进行加权。
本文将CA注意力机制放置在ASPP之后,可以将不同膨胀率的特征图使用坐标注意力机制进一步优化图像特征,ASPP输出的特征图在通道维度上可能存在冗余或不均衡,CA注意力机制能够对ASPP输出的通道信息进行优化,增强重要通道的响应,抑制噪声或不重要的通道。捕捉多尺度上下文信息,增强模型的选择性,减少信息丢失,从而识别出哪些特征通道更为重要,通过CA注意力机制对ASPP输出进行优化后,能够为特征融合提供更干净、更有效的特征,以此提升分割模型的性能。
1.5.3 损失系数
在DeepLabV3+模型中默认使用的是交叉熵损失函数(Cross-EntropyLoss, CE_Loss),它是图像分割任务中的标准损失函数,可以有效地处理类别平衡的数据集。但在本文的胡麻倒伏区域识别中,正常未倒伏的作物远多于倒伏的作物,导致类别分布不平衡;此外,倒伏的胡麻作物可能因为遮挡、光照不足、成像角度等因素难以被准确识别。因此,传统的CE_Loss可能在作物倒伏识别上不会有很好的表现。针对这些因素,本文模型对损失函数进行改进,将CE_Loss替换为Focal Loss[28],其计算式为
![]()
式中FL为Focal Loss,Pt是模型对于样本的预测概率,当样本为正例时,Pt=P,当样本为负例时,Pt=1-P,P为模型预测该样本为正例的概率。at是平衡正负样本的权重因子,通常取值为0.25或0.75,r是调节因子,用于控制难易样本的权重,通常取值为2。此外,添加Dice Loss到总损失中。Dice Loss的计算式为
![]()
式中DL为Dice Loss,X是预测的分割结果,Y是真实的分割标签。∣X∩Y∣表示预测结果和真实标签的交集元素个数,∣X∣和∣Y∣分别表示预测结果和真实标签中的元素个数。在使用中,为了避免分母为零的情况,加入一个平滑项ε。改进后的计算式为
![]()
式中ε的值为10−6。混合Focal Loss+ Dice Loss的损失函数可以让倒伏识别更加精确。Focal Loss可以通过增加难以分类样本的权重以及减少容易分类样本的权重帮助模型更好地学习那些难以识别的倒伏区域,并且有助于在类别不平衡的情况下有更佳的表现,提高倒伏区域的识别能力。对于Dice Loss而言,它直接衡量预测分割区域和真实标签之间的重叠程度,这对于图像分割任务特别重要,并且它会鼓励模型预测到更准确的边界。
1.6 试验环境及评估参数
1.6.1 试验环境设置
本试验基于高性能的硬件配置搭建。在图形处理方面,采用RTX4090D显卡,显存达24GB,能够高效处理复杂的图形计算任务,为深度学习中的图像相关试验提供强大的算力支持。中央处理器选用AMD EPYC 9754(128核),具备多核心运算能力,可满足大规模数据并行处理需求。内存为60GB,能够保障在运行复杂程序和处理大量数据时的流畅性。为了验证本次试验中改进的DeepLabV3+网络的识别效果,将其与HRNet[29]、PSPNet[30]、U-Net[31]、SegNeXt-S[32]、DeepLabV3+等分割模型进行比较。网络模型的搭建与训练是在Python3.8.10运行环境以及Pytorch1.7.1深度学习框架中完成的。优化器设置为SGD,最大学习率设置为0.001,最小学习率设置为0.00001,学习率采用余弦学习率衰减(cosine learning rate decay)[33]进行调整。模型设置批次大小batch_size为30,总训练轮次设置为200轮,试验所需模型均可收敛。
1.6.2 模型评估指标
在语义分割领域,常用的评价指标包括平均交并比(mIoU)、平均像素精度(mPA)、平均精确率等,本文主要采用这3种评估指标。
平均交并比(mIoU)为:
![]()
平均像素精度(mPA)为:
![]()
式中,k表示分类任务中的类别数量。Pii表示模型正确预测为第i类的样本数量,其中两个下标i分别代表真实类别和预测类别。Pij代表模型将真实类别为j的样本预测为类别i的样本数量。Skj=0Pij对第i个预测类别下,从第0类到第k类的预测样本数量求和,也就是模型预测为第i类的样本总数。1/k+1为加权系数,在计算mPA时对各类别精度进行加权。
2 结果与分析
2.1 改进模型的消融试验为了验证改进后各模块
为了验证改进后各模块的有效性,对模型进行消融试验。结果如表1所示。
表1 DeepLabV3+各模块消融试验对比
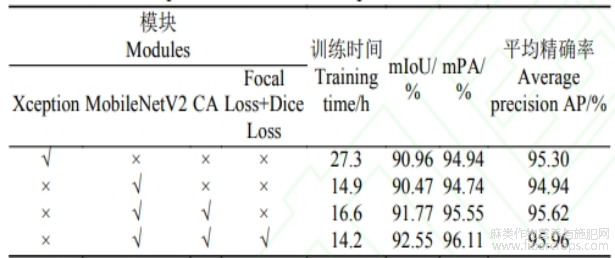
注:“√”表示加入该模块,“×”表示未加入该模块,mIoU为平均交并比mPA为平均像素精度。
通过试验可以看到,在200轮的训练中,将主干网络替换为MobileNetV2之后,模型的训练效率提高,训练时间减少了12.4h,mIoU以及mPA分别仅下降了0.49和0.20个百分点,在仅牺牲少量精度的前提下,大幅度降低了模型的训练成本。在此基础上增加CA注意力机制后,训练时间小幅度增加的同时,模型的mIoU以及mPA分别上涨了1.30和0.81个百分点,表明CA机制在一定程度上提升了模型的精度。在之前的基础上更换损失函数,模型效果提升最为显著,训练时长达到14.2h,模型的mIoU以及mPA也分别达到了92.55%和96.11%,对比其他试验mIoU分别提升1.59、2.08和0.78个百分点,mPA分别提升1.17、1.37和0.56个百分点。此次消融试验有效的验证了各个改进模块的效果,在效率和精度两方面均得到了一定程度的提升。
2.2 不同模型的对比试验
经过200轮训练后,SegNeXt-S模型的整体表现相对欠佳,其mIoU与mPA指标低于其他模型。PSPNet在各项评估指标中高于SegNeXt-S,从训练耗时来看,PSPNet与SegNeXt-S模型训练分别耗时19.2和19.0h(表2),对比其他模型,两者的准确率和效率均相对较低。这表明PSPNet与SegNeXt-S在处理胡麻倒伏时的复杂场景不如其他模型。U-Net的表现优于PSPNet,表明其在处理倒伏数据像素级别的分割任务中具有更好的性能。U-Net的对称编码-解码结构可能有助于更好地捕捉细节信息,虽然其精度并不很高,但其在模型训练时间上相比PSPNet有很大的优势。DeepLabV3+在200轮训练后,各项指标均优于PSPNet和U-Net,尤其是在mIoU和平均精确率上表现突出。DeepLabV3+通过引入空洞卷积和多尺度特征融合,能够更好地处理不同尺度的物体,从而提升了分割精度。但是其在模型训练时间上达到了27.3h,表明了模型本身计算量大,训练速度慢等特点。
表2 各模型训练数据对比
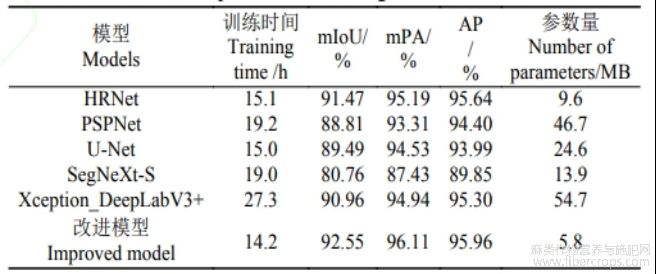
因此本文对于DeepLabV3+进行了更加轻量化的改进,改进的DeepLabV3+在胡麻倒伏识别中表现最佳,mIoU达到了92.55%,mPA为96.11%,平均精确率为95.96%,表明改进后的DeepLabV3+能够更好地捕捉胡麻倒伏区域的关键特征。相较于原始的DeepLabV3+,改进后的模型在mIoU、mPA、平均精确率上均有提升,并且在精度和训练速度上均优于训练表现最优的HRNet。同时,在模型的训练时间上,减少至14.2h,训练速度得到了极大的提升。
2.3 不同分割模型训练结果
基于自建的胡麻倒伏数据集,试验分别对HRNet、PSPNet、U-Net、SegNeXt-S、DeepLabV3+以及本文提出的改进模型分别测试了其分割性能,其损失曲线如图5所示,各个模型的损失曲线均进行了平滑处理,各个模型在200轮的训练批次下均已达到收敛。
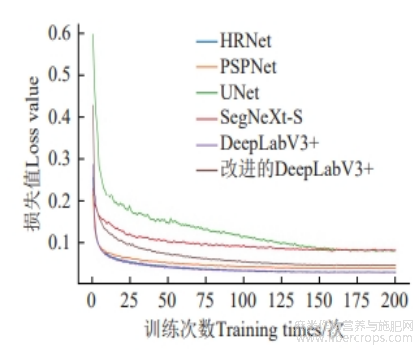
图 5 各模型对比试验损失曲线
通过观察图6中的模型训练后的预测结果,可以发现SegNeXt-S对于分割边界划分的十分模糊且存在较为明显的错误识别现象,其分割效果较差。PSPNet、HRNet、U-Net、DeepLabV3+四种模型也存在类似现象,改进后的模型能够更加准确的捕捉倒伏的边缘信息,降低边界模糊现象,在倒伏边界上有更好的清晰度,与标注图像相比改进后模型与真实情况更为吻合,减少了错误识别的情况,能够更加清晰的将倒伏区域从背景中分离出来,提高分割的精确率。对于小面积的识别情况也超过其他模型。对于整体视觉效果而言,改进后的效果也更加接近真实倒伏区域。


图6 各模型对胡麻倒伏识别效果对比
2.5 改进模型在公共数据集上的表现
为验证本文改进模型的可靠性和泛化能力,将本文改进模型在公共数据集上进行验证,引用2020年发布的AgriculturalField-Seg数据集[34],该数据集由1200张农业田间分割图像组成,包括3300多块农田。本文通过使用DeepLabV3+基础模型以及本文改进模型的分割效果进行对比,模型训练轮次设置为150轮,结果如表3所示,以验证本文改进模型的有效性。
表3 公共数据集训练表现
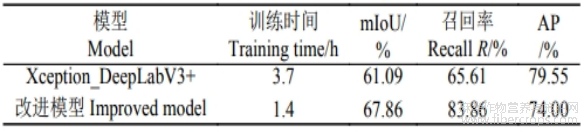
本文将模型统一训练150轮,模型均可收敛,可以看到,本文改进的模型在此数据集上的性能表现也较为突出,相比基础的DeepLabV3+模型,在少量牺牲mPrecision的同时,训练时长大幅度降低,由3.7h降低至1.4h,mIoU、召回率(recall,R)均有大幅度提升。
3 结论
本文通过融合坐标注意力机制、更换模型轻量化主干网络和损失函数对DeepLabV3+模型进行改进,达到了对胡麻倒伏区域的识别效果以及农机收割时对实时性倒伏识别的预期要求。主要研究结论如下:
1)改进后的模型在自建数据集上的平均精确率可以达到95.96%,对比其他基础模型而言均有不同程度的提升。改进后的模型mPA和mIoU分别达到了92.55%和96.11%,验证了其在胡麻倒伏区域识别的有效性。
2)试验结果表明,改进后的DeepLabV3+模型对4032×2268像素超高分辨率农田影像的单帧处理时间仅为12.05ms(83帧/s),理论上可支持收割机在2m/s及更快的速度范围内的稳定作业,在83帧/s处理速度下,系统可实现每2.4cm(以2m/s作业速度计)完成一次倒伏检测,证实了其在真实农机场景中的技术可行性。
本文自建的数据集虽然在改进后的模型上识别精度较高,但在方法上存在一定的不确定性。由于更换的损失函数更加适用于分割类别不平衡的数据,本文改进的模型在目标类别数量较少的数据集上会表现更优。此外,由于分割类别仅判断了是否倒伏,未对倒伏级别进行分类,现有的方法可能会导致收割机在调整割台时无法精确的匹配实际的倒伏高度。未来在倒伏识别的研究中,将进一步收集多种倒伏程度不同的数据,为收割机割台的调整提供更加完善的数据支撑。
参考文献
[1] 王利民,张建平,党照,等.胡麻两系杂交亲本的配合力及杂种优势分析[J].中国农业科学,2016,49(6):1047-1059.
[2] 李东坡,梁成华,武志杰,等.缓/控释氮素肥料玉米苗期养分释放特点[J].水土保持学报,2006,20(3):166-169.
[3] 杨东贵,陆万芳.倒伏对胡麻农艺性状及品质的影响[J].甘肃农业科技,2012(11):15-17.
[4] 张红,熊龙驰,颜宏烨,等.韭菜气力扶禾装置的设计[J].包装与食品机械,2025,43(1):48-53.
[5] 赵立新,李繁茂,李彦,等.基于无人机平台的直立作物倒伏监测研究展望[J].中国农机化学报,2019,40(11):67-72.
[6] 周平,周恺,刘涛,等.水稻倒伏监测研究进展[J].中国农机化学报,2019,40(10):162-168.
[7] 赵静,潘方江,兰玉彬,等.无人机可见光遥感和特征融合的小麦倒伏面积提取[J].农业工程学报,2021,37(3):73-80.
[8] 李广,张立元,宋朝阳,等.小麦倒伏信息无人机多时相遥感提取方法[J].农业机械学报,2019,50(4):211-220.
[9] 杨蜀秦,王鹏飞,王帅,等.基于MHSA+DeepLabv3+的无人机遥感影像小麦倒伏检测[J].农业机械学报,2022,53(8):213-219,239.
[10] 申华磊,苏歆琪,赵巧丽,等.基于深度学习的无人机遥感小麦倒伏面积提取方法[J].农业机械学报,2022,53(9):252-260+341.
[11] 郑二功,田迎芳,陈涛.基于深度学习的无人机影像玉米倒伏区域提取[J].河南农业科学,2018,47(8):155-160.
[12] 臧贺藏,王从胜,赵巧丽,等.基于深度学习的小麦倒伏自动分类方法研究[J].河南农业科学,2023,52(11):167-173.
[13] 郑权,乔江伟,李婕,等.融合多尺度特征和注意力机制的油菜倒伏分类[J].农业工程学报,2024,40(11):186-194.
[14] 王薇,付虹雨,卢建宁,等.基于无人机航拍的苎麻倒伏信息解译研究[J].中国农业科技导报,2024,26(3):91-97.
[15] 刘美辰,田勇鹏,王璐,等.收获作业时小麦倒伏检测方法[J].农机化研究,2019,41(2):40-44,54.
[16] WEN J, YIN Y, ZHANG Y, et al. Detection of wheat lodging by binocular cameras during harvesting operation[J]. Agriculture,2022,13(1):120.
[17] 杨悦,刘阳春,周海燕,等.基于激光雷达的稻麦倒伏区域实时监测方法[J].农业工程学报,2025,41(9):125-133.
[18] 张敏.基于机器视觉的稻麦联合收割机田间信息实时监测系统研究[D].镇江:江苏大学,2021.
[19] N L C, ZHU Y, PAPANDREOU G, et al. Encoder decoder with atrous separable convolution for semantic image segmentation[C]//ComputerVision-ECCV 2018. Munich: Springer,2018:833-851.
[20] PENG H, ZHONG J, LIU H, et al. Resdense-focal-deeplabv3+ enabled litchi branch semantic segmentation for robotic harvesting[J]. Computers and Electronics in Agriculture,2023,206:107691.
[21] 邓向武,梁松,齐龙,等.基于DeepLabV3+的稻田苗期杂草语义分割方法研究[J].中国农机化学报,2023,44(4):174-180.
[22] SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: Inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,2018:4510-4520.
[23] 黄海新,贺朝,程寿山,等.基于改进DeepLabV3+的钢桥锈蚀检测方法[J].重庆交通大学学报(自然科学版),2025,44(2):18-24,60.
[24] 闫河,雷秋霞,王旭.融合注意力机制的改进型DeepLabv3+语义分割[J].光学精密工程,2025,33(1):123-134.
[25] 俞高红,王一淼,甘帅汇,等.改进DeepLabV3+算法提取无作物田垄导航线[J].农业工程学报,2024,40(10):168-175.
[26] 林桂潮,徐垚,曾文勇,等.融合语义分割和三维点云分析的果园障碍物实时重构方法[J].农业工程学报,2024,40(16):180-187.
[27] HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Nashville,2021:13713-13722.
[28] LIN T-Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. Salt Lake City,2017:2980- 2988.
[29] SUN K, DENG J, LIU Y, et al. Deep high-resolution representation learning for human pose estimation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, 2019:5693-5703.
[30] ZHAO H, SHI J, QI X, et al. Pyramid scene parsingnetwork[C]//Proceedings of the IEEE International Conference on Computer Vision. Honolulu,2017:2881-2890.
[31] RONNEBERGER O, FISCHER P, BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI). Munich,2015:234-241.
[32] GUO M H, LU C Z, HOU Q, et al. SegNeXt: Rethinking convolutional attention design for semantic segmentation[C]//Advances in Neural Information Processing Systems (NeurIPS).Virtual Event,2022:1140-1156.
[33] 李柏森,鲁宝亮,安国强,等.基于UNet++卷积神经网络的重力异常三维密度反演[J].地球物理学报,2024,67(2):752-767.
[34] TORRE M, RESESEIRO B, RADEVA P, et al. DeepNEM: Deep network energy-minimization for agricultural field segmentation[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2020,13:726-737.
文章摘自:范翔宇,李玥,魏霖静,等.面向收割机影像的轻量化DeepLabV3+胡麻倒伏识别方法[J].农业工程学报,1-8[2025-10-07]。
