作者:黄晶等
来源:
发布时间:2021-10-10
Tag:
点击:
[麻进展] 基于近红外光谱法鉴别不同麻类纤维
摘 要:各麻类纤维的外观形态和化学性能相似,为鉴别不同麻类纤维,基于傅里叶变换近红外光谱分析方法,采用主成分分析结合SIMCA模式识别方法,对苎麻、亚麻、大麻、黄麻、红麻、罗布麻6种纤维进行鉴别。结果表明:6种纤维经平滑及基线校正光谱预处理,构建主成分因子为3的分析模型,结合SIMCA模式识别方法,所有纤维的识别率和拒绝率达到100%,成功实现纤维鉴别。为不同麻类纤维鉴别提供了简便、无损、快速、准确的鉴定方法。
关键词: 麻纤维;测试;近红外光谱;主成分分析;SIMCA 模式识别
麻属于天然植物纤维,是纺织行业重要的原料,通常分为韧皮纤维和叶纤维两类。麻纤维吸湿好、强度高、纤维挺爽,常用的有苎麻、亚麻、大麻、黄麻、红麻、罗布麻等。由于这些纤维外观形态和化学性能相似,因此如何对其进行准确、快速鉴别值得深入研究。近年来,学者采用不同的测试手段实现了不同麻类纤维的鉴别。王成云等利用三维旋转方向试验、X-荧光光谱测试、红外光谱测试等手段,建立了常用麻纤维属性系统鉴别方法。高路等借助扫描电镜、光学显微镜测量大麻、黄麻、亚麻、苎麻等,利用其横截面特征及纤维直径差异成功实现了麻纤维鉴别。赵向旭采用显微镜法并结合纤维细度分布特征对苎麻、亚麻、大麻、黄麻、剑麻、罗布麻纤维等进行鉴别。任清庆等通过纤维纵横向形态和红外光谱图吸收峰差异区分大麻、苎麻、亚麻纤维。王雪通过扫描电镜和红外光谱技术有效鉴别了亚麻、大麻、洋麻、黄麻纤维。张光霞等采用纤维细度仪结合偏振光显微镜定性鉴别亚麻、苎麻、大麻、罗布麻、黄麻纤维。鉴别不同麻类纤维的方法有很多。常用的旋转方向法、着色法、燃烧法操作麻烦且易受人为因素影响;偏振光显微镜法无量化指标,需辅以其他手段进行判别;扫描电镜法和显微镜观察法制样麻烦且对检测人员经验要求高;红外光谱法操作简便但分析过程复杂。近红外光谱法简便、无损、快速、准确。本文基于近红外光谱法,采用主成分分析结合SIMCA模式识别,对不同麻纤维进行定性鉴别,建立了6种麻纤维的判别模型,判别准确率达100%。
1 材料
1.1 样品来源
本文采用的6种麻纤维及产地分别为:新疆罗布麻、法国亚麻、安徽苎麻、大麻、黄麻和红麻。
1.2 仪器设备参数
选择ThermoAntaris型近红外光谱仪,配有积分球漫反射采样模块。光谱扫描范围4000~12500cm-1,光谱分辨率8cm-1,扫描32次。
2 试验方法
2.1 样品制备
将6种麻纤维样品切碎成约3cm×0.5cm×0.5cm的小段,均匀混合,使用FZ109型植物粉碎机分别将6种麻纤维样品粉碎,选取其中过60目筛的样品,置于恒温恒湿环境中24h备用。
2.2 数据采集
每种纤维取约1g置于直径18mm的圆柱形样品杯中,充分压实,经旋转积分球漫反射方式扫描得到近红外光谱。考虑到麻纤维成分的差异性大,每个样品取样35次。
2.3 数据处理方法
本文的光谱曲线中包含2205个变量,但并不是所有的变量都同等重要。因此,需要减少数据维度来提取合适的变量用于后续分析。采用化学计量法中主成分分析(PCA)方法,即无监督模式识别分析来选取感兴趣的变量,之后采用SIMCA,即监督式模式识别方法实现对纤维的鉴别。主成分分析是多元统计分析中常用的一种方法,它在尽可能保留原数据信息的基础上通过一个特殊的特征向量矩阵将高维空间的数据投影到较低维的空间中,最终将一组可能存在相关性的变量转换为一组线性不相关的变量。SIMCA分类方法建立在主成分分析的基础上,该算法的基本思路为对训练集中的每一类样本的光谱数据矩阵进行主成分分析,建立每一类的主成分分析模型。然后,SIMCA模型在给定的置信区间内定义子空间,并将样本投影到每个子空间中,计算子空间之间的距离。一般来说,两个群体之间的类间距离越大,分离越好。据此,可以实现对未知样品的自动分类。
3 结果分析
3.1不同麻类纤维的近红外光谱图
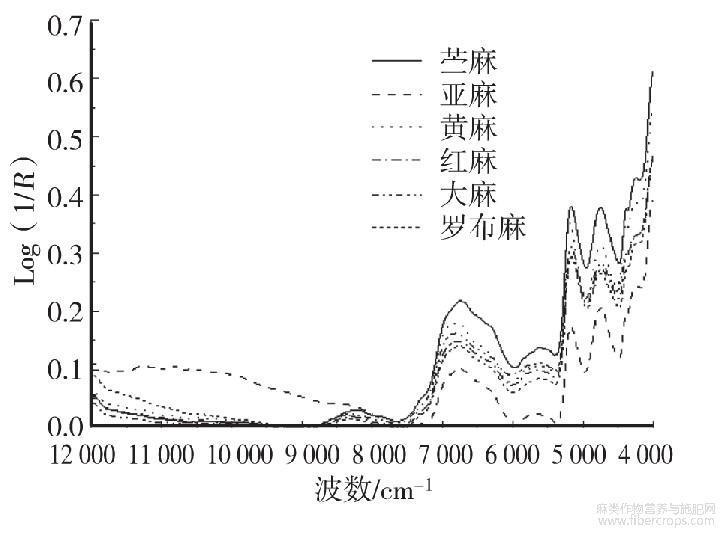
图1 不同麻类纤维的近红外平均光谱
从图1可以看出,这些近红外光谱特征相似峰的个数相同,曲线走势相近,难以直观鉴别分类。因此,需要通过合适的方法分析光谱数据,提取特征信息,实现样品的定性鉴别。
3.2 光谱数据的预处理
在近红外光谱分析中,建模数据是建立数学模型的原始信息,它应包含分析样品的全部特征信息。但实际上近红外光谱仪所采集的光谱数据除包含样品的自身信息外,还含有其他无关信息和噪声,如电噪声、样品背景、杂散光等。为消除光谱数据无关信息和噪声干扰,需进行适当的光谱预处理。
常用的方法有平滑处理、基线校正、多元散射校正和标准正态变量校正等。本试验采用平滑处理及基线校正对光谱进行预处理来消除这些因素的干扰,提高建模的预测精准性和稳定度。
3.3 纤维鉴别主成分分析
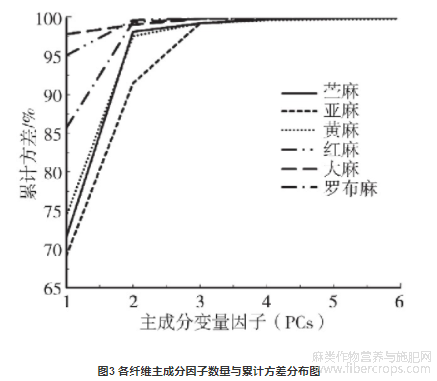
从6种纤维中随机选择25条光谱作为训练集,剩余的10条光谱作为预测集,利用6种纤维的训练集光谱构建各自的主成分模型。在主成分分析模型中,主成分变量因子的选取对分析结果有着重要的作用。主成分因子对应方差值越大,表示该因子所包含的信息越多,通常光谱数据的转变主要体现在前面的几个主成分因子中。图3为6种模型中,主成分因子数量与累计方差的分布图。可以看出,当主成分因子为3时,6种模型的方差高达97%以上,因此在6种主成分模型中,同时选择前3个主成分变量因子,将2205个变量转化为3个主成分变量因子。图4为PC=3的主成分模型中6种纤维的三维分布。
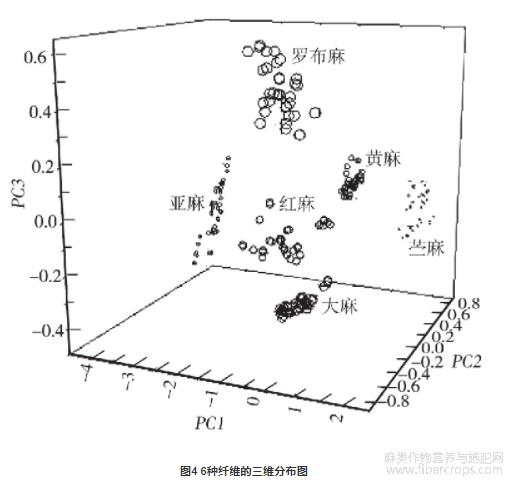
从图4可以看出,6种纤维各占据不同的位置,同种纤维堆簇在一起,这从宏观上代表了纤维的分类。
3.4不同麻类纤维光谱定性分析模式识别
基于各类主成分分析模型,利用有监督的SIMCA模式识别方法,建立6种麻类纤维的校正子集模型,然后计算未知样本与主成分分析模型的距离,根据类间距评价聚类结果好坏。类间距越大,说明类与类之间差异越明显,分离越好。6种纤维相对分布距离见表1。
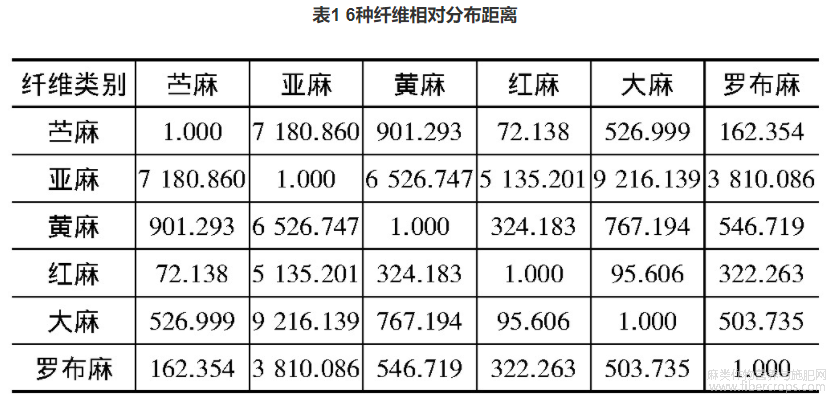
由表1可见,苎麻、红麻两类纤维的位置较接近,其余纤维两两间的距离都很远,表明SIMCA分类模型能较好地区分6种纤维。
识别率与拒绝率是充分反映模型间聚类可信度的常用指标。识别率表征某类样品有多少落在该类模型的区域内,拒绝率表征某类样品对异类样品的拒绝程度。如识别率及拒绝率均为100%,认为两类样品之间没有重叠,聚类分开效果明显。在SIMCA识别模式中,6种纤维的训练集识别率均为100%(25/25),拒绝率均为100%(125/125)。将6种纤维的预测集导入6种主成分分析模型,通过显著性对比,所有纤维的识别率均为100%(10/10),拒绝率均为100%(50/50),实现了对麻类纤维的鉴别。上述识别模式中,置信区间为95%。
4 结语
本文通过采集不同麻类纤维的近红外光谱,结合光谱预处理,在主成分分析的基础上进一步使用SIMCA模式识别技术,成功鉴别多种麻类纤维。主成分分析模型中,选取主成分变量因子为3。SIMCA模式识别分析中,根据类间距、识别率与拒绝率等数据得到分类结果。试验结果表明:苎麻、亚麻、大麻、黄麻、红麻、罗布麻纤维判别准确率达100%,该方法为麻类纤维的鉴别提供了一种快速、无损、简便、准确的新方法。
文章摘自:黄晶,郁崇文.基于近红外光谱法鉴别不同麻类纤维[J].上海纺织科技,2021,49(01):49-51+60.
更多阅读
Copyright by Ramie Research Institute of Hunan Agricultural University
湖南农业大学农学院/苎麻研究所 版权所有 2009-2016 湘ICP备10006838号-1
